
In financial services, AI-assisted data engineering is no longer just a productivity story. It has an opportunity to accelerate growth at scale. The harder question is whether banks, insurers and asset managers can make faster Snowflake delivery auditable, repeatable, and safe.
A Financial Services perspective on governed AI-assisted Snowflake delivery
The pressure rarely announces itself as a transformation program. It appears as a risk team waiting for a new exposure view, a finance function trying to close another reconciliation gap, or a product team asking why trusted profitability data still takes so long to assemble. In financial services, these delays are not merely technical. They reveal how the organization turns data work into governed change.
Snowflake Cortex Code arrives in that setting as a useful provocation. It can help with SQL, Python, Snowpark, notebooks, pipeline development, account administration and review preparation. It is a Snowflake-native AI coding agent, which means it is closer to the data platform than the general-purpose coding assistants many teams have experimented with over the past two years.
That closeness matters, but it does not settle the question. Regulated firms do not only need work to happen faster. They need to know which data was used as context, which permissions were in force, what was generated, who reviewed it, which tests passed, and whether the resulting pattern should be reused. The breakthrough is not the prompt. It is the operating model around it.
The first mistake is to treat Cortex Code as a side tool for individual productivity. That may produce local gains, but it can also create local variation: different teams prompting differently, reviewing differently and documenting differently. The more consequential approach is to make AI-assisted delivery part of the firm’s common engineering discipline.
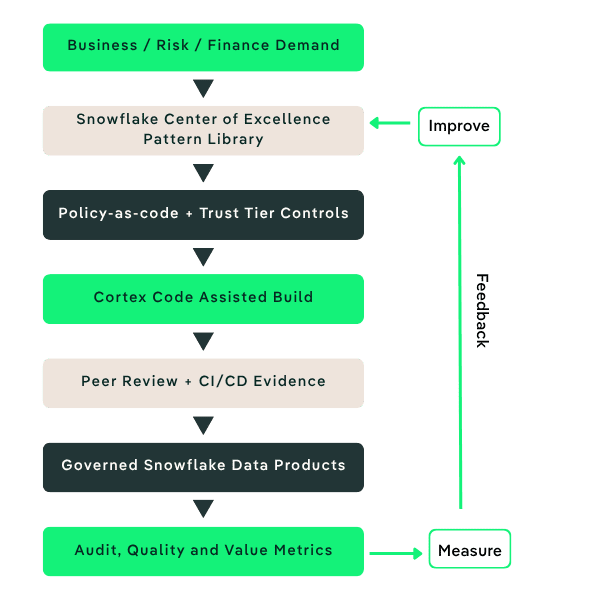
The shift from activity to capability
A modern data operating model for Cortex Code starts before the first prompt. It needs clear trust tiers, approved examples, reusable Snowflake patterns, data quality expectations, review checklists and CI/CD evidence. These are not bureaucratic extras. They are the conditions that let an organization use AI without losing the ability to explain itself.
The best starting point is a small number of high-value use cases where the delivery pattern can be reused: regulatory reporting, finance reconciliation, risk analytics, client profitability or operational data quality. A risk analytics workflow can be documented as it is built rather than reconstructed after the fact. In each case, Cortex Code may speed up the work, but the operating model decides whether the output is admissible.
In practical terms, Cortex Code can help teams scaffold a regulatory reporting pipeline with tests and lineage notes, prepare a finance reconciliation pattern with exception handling, or generate documentation for a risk analytics data product. An efficient model ensures those outputs are checked against policy-as-code, peer review, CI/CD evidence and measurable delivery outcomes before they become production practice.
Success should be measured in both speed and control. Useful indicators include PR cycle time, scaffold time, CI pass rate, defect density, data quality exceptions, standards conformance and the percentage of new delivery work reusing approved patterns. Those measures keep the program honest: Cortex Code adoption should improve delivery performance without creating a shadow process.
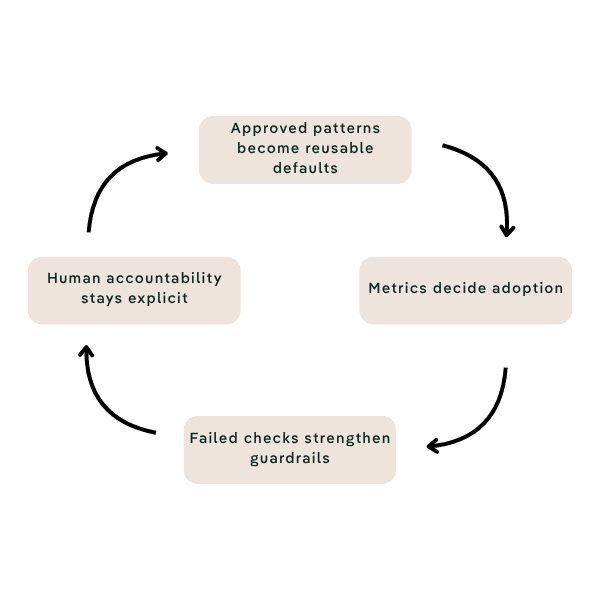
There is a broader lesson here for the modern data model. The next phase is not simply about where data lives or which platform hosts it. It is about how an organization learns. Each approved pattern becomes a new default. Each failed check strengthens the guardrail. Each delivery cycle should leave behind something the next team can use.
Watch
Cycle time, CI pass rate, defects and data-quality exceptions
Reuse
Approved patterns, safe examples, and common Snowflake playbooks.
Learn
Every delivery cycle should improve the next team’s starting point.
Kubrick works with financial services organizations to make that shift practical: assessing Cortex Code readiness, selecting governed pilot use cases, designing trust tiers, building reusable pattern libraries and enabling the client’s own Snowflake Center of Excellence. The aim is not a louder AI story. It is faster Snowflake delivery that leaves evidence behind.



